
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 | 31 |
- 바로학교
- 장고
- 추천 영상
- 단축어
- nocookie
- docker-compose
- 그리디 알고리즘
- flask
- 탐욕 알고리즘
- Google Drive
- List
- 충북
- MongoDB
- 리스트
- selenium
- Django
- DB
- 유튜브
- G-Suite
- 코딩
- 파이썬
- 알고리즘
- 링크
- pymongo
- gpu 병렬처리
- venv
- 아이폰
- python
- 구글 드라이브
- 깃허브
- Today
- Total
SSAMKO의 개발 이야기
beautifulSoup 불가 페이지 selenium으로 크롤링하기 본문
python으로 크롤링(웹 스크래핑)을 할 때 beautiful soup은 굉장히 강력한 도구입니다.
하지만, 동적페이지 중 데이터를 따로 받아서 완성시키는 페이지들은 beautiful soup으로 가져오려고 하면 엉뚱한 데이터들이 가져와지거나 실패하는 경우가 종종 생깁니다.
물론 그런 페이지들도 beautiful soup을 집요하게 파고들면 스크랩이 가능한 것 같지만,
selenium을 이용하면 훨씬 간단하게 그런 페이지들을 스크래핑 할 수 있습니다.
selenium은 chrome을 이용해 실제 페이지를 띄우고 우리가 키보드 마우스로 하는 동작들을 자동화해주는 라이브러리입니다.
그럼 bs로 (쉽게) 가져올 수 없는 페이지 중에서
'네이버 증권 > 국내 증시 > 시가 총액' 페이지를 스크래핑해보도록 하겠습니다.

위 페이지에서 '종목명'과 '현재가'를 가져와 보도록 하겠습니다.

위와 같은 결과가 나오도록 코딩을 해보겠습니다.
먼저 bs4를 이용해 스크랩하기 위해 페이지 구조를 살펴보도록 하겠습니다.
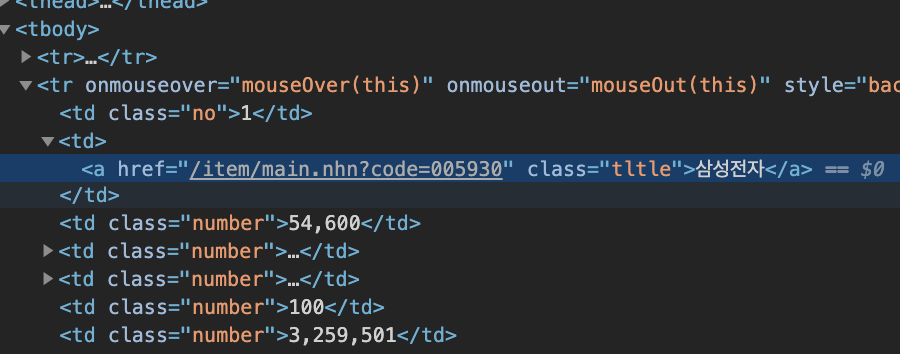
먼저 종목명은 table 안에 두 번째 셀에 a태그 안에 들어있네요.

정확한 selector주소를 구하기 위해 크롬개발자 도구를 이용합니다.
#contentarea > div.box_type_l > table.type_2 > tbody > tr:nth-child(2) > td:nth-child(2) > a이번 포스팅의 목적은 bs4 사용법이 아니기때문에 이후 과정은 생략하도록 하겠습니다.
이렇게 해서 bs4를 이용한 스크래핑 코드를 작성해보면
import requests
from bs4 import BeautifulSoup
headers = {'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'}
data = requests.get('https://finance.naver.com/sise/sise_market_sum.nhn',headers=headers)
soup = BeautifulSoup(data.text, 'html.parser')
stocks = soup.select('#contentarea > div.box_type_l > table.type_2 > tbody > tr')
for stock in stocks:
a_tag = stock.select_one('td:nth-child(2) > a')
if a_tag is not None:
price = stock.select_one('td:nth-child(3)').text
name = a_tag.text
row = {
'name': name,
'price': price
}
print(name, price)
위와 같이 작성할 수 있습니다. 그런데 스크립트를 실행시켜보면 제대로 작동하지 않습니다.
이제 여기서 selenium이 필요합니다.
기본적인 원리는 간단합니다. 우리는 이번에 selenium을 스크랩에만 이용할 것이기 때문에 간단하게 페이지가 로드된 후 html문서만 가져오는 것으로 selenium은 임무를 마치게 됩니다.
selenium을 한번도 사용해보지 않으신 분은 아래 포스팅으로 가서, 크롬드라이브 설치와 초기 세팅하는 방법을 숙지하고 오시기 바랍니다.
2020/04/22 - [Python] - Selenium 으로 간단한 매크로 만들기 | python
Selenium 으로 간단한 매크로 만들기 | python
1. selenium 설치 2. chromedriver 다운로드 3. 페이지 띄우기(e학습터) 4. 로그인 *전제) - 파이썬 설치 - 파이썬 사용경험(잘 할 필요는 없음) 1. selenium 설치 윈도우 cmd(mac 터미널)에서 pip를 사용하여 sel..
ssamko.tistory.com
from selenium import webdriver
driver = webdriver.Chrome(executable_path="/Users/ssamko/Downloads/chromedriver")
url = 'https://finance.naver.com/sise/sise_market_sum.nhn'
driver.get(url)
soup = BeautifulSoup(driver.page_source, 'html.parser')
추가/변경할 코드는 위와 같습니다.
기존의 request로 page를 가져오던 것에서 selenium으로 page를 가져오는 것으로 바뀐 것 뿐, 나머지 bs4 코드는 그대로 사용하면 됩니다.
전체 코드는 아래와 같습니다.
from selenium import webdriver
from bs4 import BeautifulSoup
driver = webdriver.Chrome(executable_path="/Users/ssamko/Downloads/chromedriver")
url = 'https://finance.naver.com/sise/sise_market_sum.nhn'
driver.get(url)
soup = BeautifulSoup(driver.page_source, 'html.parser')
stocks = soup.select('#contentarea > div.box_type_l > table.type_2 > tbody > tr')
for stock in stocks:
a_tag = stock.select_one('td:nth-child(2) > a')
if a_tag is not None:
price = stock.select_one('td:nth-child(3)').text
name = a_tag.text
row = {
'name': name,
'price': price
}
print(name, price)
driver.quit()selenium과 bs4의 조합으로 더 풍부한 크롤링을 경험하시기 바랍니다 :)
'Python' 카테고리의 다른 글
| Django에서 socket-io[client] 사용하기 | Python (0) | 2020.06.28 |
|---|---|
| api로 받은 정보 telegram으로 보내기 | python (0) | 2020.06.19 |
| CT로 현실 문제 해결하기(1) - 정보시스템 관리대장 (0) | 2020.05.02 |
| 바로학교 출결점검 v2.0 (3) | 2020.04.26 |
| 바로학교 출결점검 v1.1 | 오류 안내 (7) | 2020.04.23 |



